
本記事は、Tensorflowの本家サイト「tf.contrib.learn Quickstart」 を翻訳(適宜意訳)したものです。誤り等あればご指摘いただけたら幸いです。
はじめに
TensorFlowの高度な機械学習API(tf.contrib.learn)によって、さまざまな機械学習モデルの定義、訓練、評価が簡単になります。このチュートリアルでは、tf.contrib.learnを使用してニューラルネットワーク分類器を構築し、それをIrisデータセットを用いて学習し、がく(sepal) / 花びら(petal)の幾何学に基づいて花の種類を予測します。次の5つのステップに沿って、実行コードを記述していきます。
- Irisトレーニング/テストデータを含むCSVをTensorFlow
Datasetにロードする - ニューラルネットワーク分類器1を構築する
- トレーニングデータを使用してモデルに学習させる
- モデルの精度を評価する
- 新しいサンプルを分類する
注:このチュートリアルを開始する前に、TensorFlowをインストールしてください。
ニューラルネットワークのソースコード
ニューラルネットワーク分類器の完全なコードは次のとおりです。
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import urllib
import numpy as np
import tensorflow as tf
# Data sets
IRIS_TRAINING = "iris_training.csv"
IRIS_TRAINING_URL = "http://download.tensorflow.org/data/iris_training.csv"
IRIS_TEST = "iris_test.csv"
IRIS_TEST_URL = "http://download.tensorflow.org/data/iris_test.csv"
def main():
# If the training and test sets aren't stored locally, download them.
if not os.path.exists(IRIS_TRAINING):
raw = urllib.urlopen(IRIS_TRAINING_URL).read()
with open(IRIS_TRAINING, "w") as f:
f.write(raw)
if not os.path.exists(IRIS_TEST):
raw = urllib.urlopen(IRIS_TEST_URL).read()
with open(IRIS_TEST, "w") as f:
f.write(raw)
# Load datasets.
training_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TRAINING,
target_dtype=np.int,
features_dtype=np.float32)
test_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TEST,
target_dtype=np.int,
features_dtype=np.float32)
# Specify that all features have real-value data
feature_columns = [tf.contrib.layers.real_valued_column("", dimension=4)]
# Build 3 layer DNN with 10, 20, 10 units respectively.
classifier = tf.contrib.learn.DNNClassifier(feature_columns=feature_columns,
hidden_units=[10, 20, 10],
n_classes=3,
model_dir="/tmp/iris_model")
# Define the training inputs
def get_train_inputs():
x = tf.constant(training_set.data)
y = tf.constant(training_set.target)
return x, y
# Fit model.
classifier.fit(input_fn=get_train_inputs, steps=2000)
# Define the test inputs
def get_test_inputs():
x = tf.constant(test_set.data)
y = tf.constant(test_set.target)
return x, y
# Evaluate accuracy.
accuracy_score = classifier.evaluate(input_fn=get_test_inputs,
steps=1)["accuracy"]
print("\nTest Accuracy: {0:f}\n".format(accuracy_score))
# Classify two new flower samples.
def new_samples():
return np.array(
[[6.4, 3.2, 4.5, 1.5],
[5.8, 3.1, 5.0, 1.7]], dtype=np.float32)
predictions = list(classifier.predict(input_fn=new_samples))
print(
"New Samples, Class Predictions: {}\n"
.format(predictions))
if __name__ == "__main__":
main()
以下のセクションでコードを詳しく説明します。
Iris CSVデータをTensorFlowにロードする
Irisデータセットは、Irisのそれぞれの種類について、50個のサンプルを含む、150行のデータになります。(Iris setosa、Iris virginica、およびIris versicolorの3種類)

左から、Iris setosa (by Radomil, CC BY-SA 3.0), Iris versicolor (by Dlanglois, CC BY-SA 3.0), Iris virginica (by Frank Mayfield, CC BY-SA 2.0).
各列には、がくの長さ2、がくの幅3、花びらの長さ4、花びらの幅5、花の種類6など、花のサンプルごとに以下のデータが含まれています。花の種類は整数で表され、0はIris setosa、1はIris versicolor、2はIris virginicaを示します。
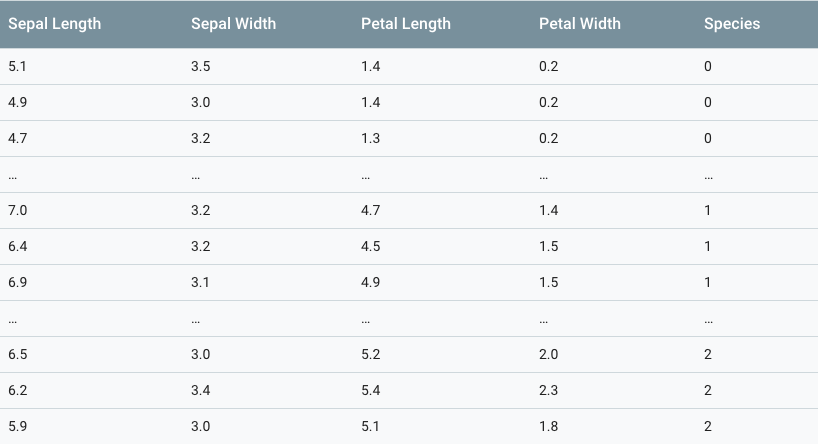
このチュートリアルでは、Irisデータがランダムに2つの別々のCSVに分割されています。
- 120サンプルのトレーニングセット(iris_training.csv)
- 30サンプルのテストセット(iris_test.csv)
まず、必要なモジュールをすべてインポートし、データセットをダウンロードして格納する場所を定義します。
from __future__ import absolute_import from __future__ import division from __future__ import print_function import os import urllib import tensorflow as tf import numpy as np IRIS_TRAINING = "iris_training.csv" IRIS_TRAINING_URL = "http://download.tensorflow.org/data/iris_training.csv" IRIS_TEST = "iris_test.csv" IRIS_TEST_URL = "http://download.tensorflow.org/data/iris_test.csv"
トレーニングセットとテストセットがローカルに保存されていない場合は、ダウンロードします。
if not os.path.exists(IRIS_TRAINING):
raw = urllib.urlopen(IRIS_TRAINING_URL).read()
with open(IRIS_TRAINING,'w') as f:
f.write(raw)
if not os.path.exists(IRIS_TEST):
raw = urllib.urlopen(IRIS_TEST_URL).read()
with open(IRIS_TEST,'w') as f:
f.write(raw)
次に、learn.datasets.baseのload_csv_with_header()メソッドを使用して、トレーニングセットとテストセットをデータセットにロードします。 load_csv_with_header()メソッドは3つの必須の引数をとります。
- filename:ファイルパスをCSVファイルに変換します。
- target_dtype:データセットのターゲット値のnumpyデータ型をとります。
- features_dtype:データセットの特徴値のnumpyデータ型をとります。
ここで、ターゲット(予測するモデルを訓練している値)は花種です。これは0-2の整数なので、適切なnumpyデータ型はnp.intになります。
# Load datasets.
training_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TRAINING,
target_dtype=np.int,
features_dtype=np.float32)
test_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TEST,
target_dtype=np.int,
features_dtype=np.float32)
tf.contrib.learnのデータセットはnamedtupleです。dataおよびtargetフィールドを利用して、特徴データとターゲット値にアクセスすることができます。training_set.dataおよびtraining_set.targetは、それぞれトレーニングセットの特徴データおよびターゲット値を含み、test_set.dataおよびtest_set.targetは、テストセットのフィーチャデータおよびターゲット値を含みます。
後のセクション「DNNClassifierをIrisトレーニングデータで訓練する」では、training_set.dataとtraining_set.targetを使用してモデルを訓練し、セクション「モデルの精度を評価する」ではtest_set.dataとtest_set.targetを使用してモデルの精度を評価します。それでは、まず次のセクションでモデルを構築しましょう。
Deep Neural Network Classifierを構築する
tf.contrib.learnには、Estimatorというあらかじめ定義されている様々なモデルが用意されています。これらのモデルを使用すると、すぐにデータのトレーニングや評価を実行することができます。ここでは、Deep Neural Network ClassifierモデルをIrisデータに合わせて設定します。 tf.contrib.learnを使用すると、わずか2行のコードでtf.contrib.learn.DNNClassifierをインスタンス化することができます。
# Specify that all features have real-value data
feature_columns = [tf.contrib.layers.real_valued_column("", dimension=4)]
# Build 3 layer DNN with 10, 20, 10 units respectively.
classifier = tf.contrib.learn.DNNClassifier(feature_columns=feature_columns,
hidden_units=[10, 20, 10],
n_classes=3,
model_dir="/tmp/iris_model")
上記のコードでは、データセット内の特徴のデータ型を指定するモデルの特徴カラムを最初に定義しています。すべての特徴データは連続しているので、特徴カラムを構築するのに使用する適切な関数であるtf.contrib.layers.real_valued_columnを利用します。データセットには4つの特徴(がくの幅、がくの高さ、花びらの幅、花びらの高さ)があります。したがって、すべてのデータを保持するには、dimensionを4に設定する必要があります。
次の引数を使用してDNNClassifierモデルを作成します。
feature_columns = feature_columns上記で定義された特徴カラムのセットhidden_units = [10、20、10]3つの隠れたレイヤーで、それぞれ10,20、および10のニューロンを含んでいますn_classes = 33つのアイリス種を表す3つのターゲットクラスmodel_dir = / tmp / iris_modelモデルトレーニング中にTensorFlowがチェックポイントデータを保存するディレクトリ。 TensorFlowによるロギングとモニタリングの詳細については、「Logging and Monitoring Basics with tf.contrib.learn」を参照してください。
トレーニング入力パイプラインの説明
tf.contrib.learn APIは、モデルのデータを生成するTensorFlowを作成する入力関数です。この場合、データはTensorFlow定数に格納できるほど小さいものです。次のコードでは、可能な限り単純な入力パイプラインを生成します。
# Define the training inputs def get_train_inputs(): x = tf.constant(training_set.data) y = tf.constant(training_set.target) return x, y
DNNClassifierをIrisトレーニングデータで訓練する
DNNclassifierモデルを設定したので、fitメソッドを使用してirisトレーニングデータを使って訓練することができます。get_train_inputsをinput_fnとして渡し、訓練するステップ数(ここでは2000)を渡します。
# Fit model. classifier.fit(input_fn=get_train_inputs, steps=2000)
モデルの状態はclassifierに保存されます。これは、必要に応じて繰り返し学習することができることを意味します。たとえば、上記は次のものと同じものになります。
classifier.fit(x=training_set.data, y=training_set.target, steps=1000) classifier.fit(x=training_set.data, y=training_set.target, steps=1000)
ただし、トレーニング中にモデルを追跡する場合は、代わりにTensorFlowのmonitorを使用してロギング操作を実行することをお勧めします。このmonitorについての詳細は、チュートリアル「Logging and Monitoring Basics with tf.contrib.learn」を参照してください。
モデルの精度を評価する
IrisトレーニングデータでDNNClassifierモデルを訓練しました。evaluateメソッドを使用してIrisテストデータの精度を確認することができます。fitと同様に、evaluateは入力パイプラインを構築する入力関数を取ります。evaluateは評価結果を含むdictを返します。次のコードは、Irisテストデータ-test_set.dataとtest_set.targetを渡して、精度を評価した結果を出力します。
# Define the test inputs
def get_test_inputs():
x = tf.constant(test_set.data)
y = tf.constant(test_set.target)
return x, y
# Evaluate accuracy.
accuracy_score = classifier.evaluate(input_fn=get_test_inputs,
steps=1)["accuracy"]
print("\nTest Accuracy: {0:f}\n".format(accuracy_score))
注:コード内の引数stepは重要です。evaluateは通常、入力の終わりに達するまで実行されます。これは一連のファイルを評価するのに最適ですが、ここで使用されている定数は、期待しているOutOfRangeErrorまたはStopIterationを投げることはありません。
完全なスクリプトを実行すると、以下に近い数値が出力されます。
Test Accuracy: 0.966667
あなたの結果は上記の数値と少し違うかもしれませんが、90%以上になるはずです。比較的小さなデータセットでも結果は悪くありません!
新しいサンプルを分類する
新しいサンプルを分類するには、estimatorのpredict()メソッドを使用します。たとえば、次の2つの新しい花のサンプルがあるとします。

predict()メソッドを使用して種を予測することができます。predictはジェネレータを返します。ジェネレータは簡単にリストに変換することができます。次のコードで、クラス予測を取得して出力しています。
# Classify two new flower samples.
def new_samples():
return np.array(
[[6.4, 3.2, 4.5, 1.5],
[5.8, 3.1, 5.0, 1.7]], dtype=np.float32)
predictions = list(classifier.predict(input_fn=new_samples))
print(
"New Samples, Class Predictions: {}\n"
.format(predictions))
結果は次のようになります。
New Samples, Class Predictions: [1 2]
したがって、最初のサンプルがIris versicoloであり、2番目のサンプルがIris virginicaであると、モデルが予測したことになります。
その他のリソース
- tf.contrib.learnの参考資料については、公式のAPIドキュメントを参照してください。
- tf.contrib.learnを使用して線形モデルを作成する方法の詳細は、「Large-scale Linear Models with TensorFlow」を参照してください。
- tf.contrib.learn APIを使用して独自のEstimatorを構築するには、「Creating Estimators in tf.contrib.learn」を参照してください。
- ニューラルネットワークモデリングとブラウザでの視覚化を試すには、「Deep Playground」をチェックしてください。
- ニューラルネットワークに関する高度なチュートリアルについては、「Convolutional Neural Networks」と「Recurrent Neural Networks」を参照してください。

