本記事は、TensorFlow(テンソルフロー)の本家サイト「Get Started – Getting Started With TensorFlow」 を翻訳(適宜意訳)したものです。
誤り等あればご指摘いただけたら幸いです。
はじめに
このガイドはあなたに、TensorFlowによるプログラミングを始めてもらうためのものです。
このガイドを利用する前に、TensorFlowをインストールしてください。このガイドを有益なものにするためには、前提条件として以下について知っておいたほうが良いでしょう。
・Pythonを使ったプログラミング
・配列について最低限の知識
・理想は、機械学習について何かしらの知識があればなお良い。しかし、もし機械学習について殆どあるいは全く知らないとしても、この記事は読んでおくべき最初のガイドになるはずです。
TensorFlowは複数のAPIを提供します。 最低レベルのAPI「TensorFlow Core」は完全なプログラミング制御処理を提供します。
TensorFlow Coreは、機械学習の研究者や、モデルを細かく制御する必要がある他の人におすすめです。より高いレベルのAPIは、TensorFlow Core上に構築されています。これらの上位レベルのAPIは、通常、TensorFlow Coreよりも学習して使用する方が簡単です。
さらに、より高いレベルのAPIは、繰り返しの作業を異なるユーザー間でより簡単でより一貫性のあるものにします。 tf.contrib.learnのような高度なAPIは、データセット、見積もり、トレーニングおよび推論を管理するのに役立ちます。
高水準のTensorFlow API1のいくつかは、まだ開発中であることに注意してください。今後、TensorFlowリリースで、いくつかのcontribメソッドが変更されるか、または廃止される可能性があります。
このガイドはTensorFlow Coreのチュートリアルから始まります。そしてその後に、tf.contrib.learnに同じモデルを実装する方法を解説します。
TensorFlow Core の原則を知ることにより、よりコンパクトな高レベルAPIを使用すると、内部的にどのように働いているかということを知ることに役立ちます。
Tensors(テンソル)
TensorFlow におけるデータの中心ユニットはテンソルです。テンソルは、任意の次元数の配列に整形されたプリミティブな値のセットで構成されています。テンソルのランク (rank) はその次元の数になります。
以下に、テンソルの例をいくつか挙げます。
3 # a rank 0 tensor; this is a scalar with shape [] [1. ,2., 3.] # a rank 1 tensor; this is a vector with shape [3] [[1., 2., 3.], [4., 5., 6.]] # a rank 2 tensor; a matrix with shape [2, 3] [[[1., 2., 3.]], [[7., 8., 9.]]] # a rank 3 tensor with shape [2, 1, 3]
TensorFlow Core チュートリアル
TensorFlow をインポートする
TensorFlow プログラムのための標準的な import ステートメントは次のように記述します。
import tensorflow as tf
これにより、PythonはすべてのTensorFlowのクラス、メソッド、シンボルにアクセスできます。TensorFlowのほとんどのドキュメントは、あなたがすでにこの記述を行っていることを前提としています。
計算グラフ
TensorFlow Coreプログラムは、2つの個別のセクションで構成されていると考えられます。
- 計算グラフを構築する
- 計算グラフの実行
計算グラフ2とは、一連のTensorFlowの操作をノードのグラフに配置したものです。
簡単な計算グラフを作成してみましょう。各ノードは、入力として0以上のテンソルをとり、出力としてテンソルを生成します。1つのタイプのノードは定数です。すべてのTensorFlow定数と同様に、入力値はなく、内部的に格納される値を出力します。node1とnode2の2つの浮動小数点テンソルを次のように作成できます。
node1 = tf.constant(3.0, tf.float32) node2 = tf.constant(4.0) # also tf.float32 implicitly print(node1, node2)
最後の行の print ステートメントによって、以下が出力されます。
Tensor("Const:0", shape=(), dtype=float32) Tensor("Const_1:0", shape=(), dtype=float32)
ノードの出力は期待した値 3.0 と 4.0 を出力しないことに注意してください。実際にノードを評価するためには、session の中で計算グラフを実行しなければなりません。セッションは、TensorFlowランタイムのコントロールと状態をカプセル化します。
次のコードは、Sessionオブジェクトを作成し、runメソッドを呼び出して、node1とnode2を評価するのに十分な計算グラフを実行します。 セッションで計算グラフを次のように実行します。
sess = tf.Session() print(sess.run([node1, node2]))
期待した、3.0 と 4.0 の値が出力されます。
[3.0, 4.0]
Tensorノードと操作を組み合わせることで、より複雑な計算3を行うことができます。たとえば、2つの定数ノードを追加して、次のように新しいグラフを作成することができます。
node3 = tf.add(node1, node2)
print("node3: ", node3)
print("sess.run(node3): ",sess.run(node3))
最後の2つの print ステートメントによって、以下が出力されます。
node3: Tensor("Add_2:0", shape=(), dtype=float32)
sess.run(node3): 7.0
TensorFlowには、計算グラフの画像を表示できるTensorBoardというユーティリティがあります。以下のスクリーンショットのように、TensorBoardがグラフを視覚化します。

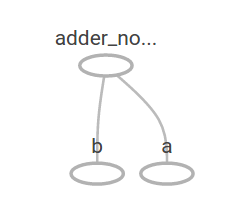
このグラフは、常に一定の結果を生むため、特に興味深いわけではありません。グラフは、プレースホルダと呼ばれる外部入力を受け付けるようにパラメータ化することができます。プレースホルダは、「後で値を提供しますよ」という約束をしてくれます。
a = tf.placeholder(tf.float32) b = tf.placeholder(tf.float32) adder_node = a + b # + provides a shortcut for tf.add(a, b)
上の3行は、関数のようなもので、2つの入力パラメータ(aとb)を定義して操作を行います。 feed_dictパラメータを使用して、これらのプレースホルダに具体的な値を提供するTensorsを指定することで、複数の入力でこのグラフを評価することができます。
print(sess.run(adder_node, {a: 3, b:4.5}))
print(sess.run(adder_node, {a: [1,3], b: [2, 4]}))
次のように出力されます。
7.5 [ 3. 7.]
TensorBoard では、グラフは以下のようになります。
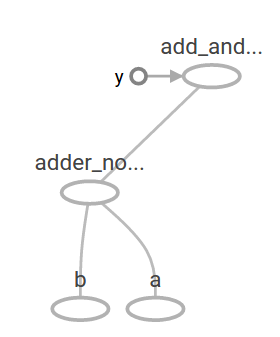
他の演算を追加することで、計算グラフをより複雑にすることができます。 例えば、以下のように記述します。
add_and_triple = adder_node * 3.
print(sess.run(add_and_triple, {a: 3, b:4.5}))
すると、出力は以下のようになります。
22.5
前の計算グラフは TensorBoard では次のように見えるはずです。
機械学習では、通常、上記のような任意の入力を取ることができるモデルが必要です。
モデルをトレーニング可能にするには、同じ入力で新しい出力を得るためにグラフを修正できる必要があります。変数は、グラフにトレーニング可能なパラメータを追加することを可能にします。以下のように、型と初期値で設定されます。
W = tf.Variable([.3], tf.float32) b = tf.Variable([-.3], tf.float32) x = tf.placeholder(tf.float32) linear_model = W * x + b
tf.constantを呼び出すと定数が初期化され、その値は決して変更できません。 それとは対照的に、tf.Variableを呼び出すと、変数は初期化されません。
TensorFlowプログラム内のすべての変数を初期化するには、次のように特別な操作を明示的に呼び出す必要があります。
init = tf.global_variables_initializer() sess.run(init)
initがすべてのグローバル変数を初期化するTensorFlowサブグラフへのハンドルであることを認識することが重要です。 sess.runを呼び出すまで、変数は初期化されません。
xはプレースホルダーなので、次のようにxのいくつかの値に対してlinear_modelを同時に評価することができます。
print(sess.run(linear_model, {x:[1,2,3,4]}))
出力は次のようになります。
[ 0. 0.30000001 0.60000002 0.90000004]
モデルを作りましたが、それがどれほど良いか分かっていません。トレーニングデータのモデルを評価するには、目的の値を提供する y プレースホルダーが必要で、損失関数を記述する必要があります。
損失関数は、現在のモデルが提供されたデータから「どれだけ期待はずれのデータだったか」を測定します。
線形回帰のための標準的な損失モデルを使用します、これは現在のモデルと提供されたデータの間の delta (差分) の二乗の合計します。
linear_model – yは、各要素が対応する例の誤差デルタであるベクトルを作成します。まず、tf.squareをその誤差を二乗します。そして次に、すべての二乗誤差を合計して、tf.reduce_sumを使ってすべての例の誤差を抽象化する単一のスカラーを作成します。
y = tf.placeholder(tf.float32)
squared_deltas = tf.square(linear_model - y)
loss = tf.reduce_sum(squared_deltas)
print(sess.run(loss, {x:[1,2,3,4], y:[0,-1,-2,-3]}))
以下のように、損失値が出力されます。
23.66
これを改善するには、Wとbの値を-1と1の完全な値に再割り当てする必要があります。
変数はtf.Variableに与えられた値に初期化されますが、tf.assignのような演算を使って変更できます。たとえば、W = -1およびb = 1は、このモデルにとって最適なパラメータです。 それに応じてWとbを変更することができます。
fixW = tf.assign(W, [-1.])
fixb = tf.assign(b, [1.])
sess.run([fixW, fixb])
print(sess.run(loss, {x:[1,2,3,4], y:[0,-1,-2,-3]}))
最終行のprint関数で、損失がゼロであるということが出力されます。
0.0
これまで上記で、WとBの完璧な値を推測しましたが、機械学習のポイントは正しいモデルパラメータを自動的に見つけることです。次のセクションでこれを達成する方法について解説します。
tf.train API
機械学習の全てをカバーする解説はこのチュートリアルの範囲外になります。
ただし、TensorFlowでは、損失関数を最小限に抑えるために各変数をゆっくりと変更するオプティマイザが用意されています。
最も単純なオプティマイザは勾配降下です。勾配降下とは、その変数に関する損失の派生の大きさに従って各変数を変更します。一般的に、シンボリック・デリバティブを手動で計算するのは単調な作業になりエラーが起こりやすいです。そのため、TensorFlowは関数tf.gradientsを使用してモデルの記述のみを与えられた関数を自動的に生成することができます。単純化のために、一般にオプティマイザがこれを行います。 以下に例を示します。
optimizer = tf.train.GradientDescentOptimizer(0.01) train = optimizer.minimize(loss)
sess.run(init) # reset values to incorrect defaults.
for i in range(1000):
sess.run(train, {x:[1,2,3,4], y:[0,-1,-2,-3]})
print(sess.run([W, b]))
この時、最終的なモデル・パラメータは以下のように出力されます。
[array([-0.9999969], dtype=float32), array([ 0.99999082], dtype=float32)]
上記の処理こそが、実際の機械学習になります! こういった単純な線形回帰を行うにはTensorFlowのコアコードはあまり必要ありませんが、モデルにデータを供給するためのより複雑なモデルや方法は、より多くのコードを記述する必要があります。
このように TensorFlow は共通のパターン、構造、そして機能のためにより高いレベルの抽象化を提供します。次のセクションで、これらの抽象概念のいくつかを使用する方法を紹介します。
完全なプログラム
以下に、トレーニング可能な線形回帰モデルのプログラムを記載します。
import numpy as np
import tensorflow as tf
# Model parameters
W = tf.Variable([.3], tf.float32)
b = tf.Variable([-.3], tf.float32)
# Model input and output
x = tf.placeholder(tf.float32)
linear_model = W * x + b
y = tf.placeholder(tf.float32)
# loss
loss = tf.reduce_sum(tf.square(linear_model - y)) # sum of the squares
# optimizer
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = optimizer.minimize(loss)
# training data
x_train = [1,2,3,4]
y_train = [0,-1,-2,-3]
# training loop
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init) # reset values to wrong
for i in range(1000):
sess.run(train, {x:x_train, y:y_train})
# evaluate training accuracy
curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x:x_train, y:y_train})
print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))
実行すると、以下が出力されます。
W: [-0.9999969] b: [ 0.99999082] loss: 5.69997e-11
こういった複雑なプログラムも、TensorBoardで可視化することができます。

tf.contrib.learn
tf.contrib.learnは、以下を含む機械学習の仕組みを簡素化する高レベルのTensorFlowライブラリです。
- トレーニング・ループを実行する
- 評価ループを実行する
- データセットを管理する
- 供給を管理する
tf.contrib.learn は多くの一般的なモデルを定義することができます。
基本的な使い方
線形回帰プログラムが tf.contrib.learn でどのくらい単純になるか見てみましょう。
import tensorflow as tf
# NumPy is often used to load, manipulate and preprocess data.
import numpy as np
# Declare list of features. We only have one real-valued feature. There are many
# other types of columns that are more complicated and useful.
features = [tf.contrib.layers.real_valued_column("x", dimension=1)]
# An estimator is the front end to invoke training (fitting) and evaluation
# (inference). There are many predefined types like linear regression,
# logistic regression, linear classification, logistic classification, and
# many neural network classifiers and regressors. The following code
# provides an estimator that does linear regression.
estimator = tf.contrib.learn.LinearRegressor(feature_columns=features)
# TensorFlow provides many helper methods to read and set up data sets.
# Here we use `numpy_input_fn`. We have to tell the function how many batches
# of data (num_epochs) we want and how big each batch should be.
x = np.array([1., 2., 3., 4.])
y = np.array([0., -1., -2., -3.])
input_fn = tf.contrib.learn.io.numpy_input_fn({"x":x}, y, batch_size=4,
num_epochs=1000)
# We can invoke 1000 training steps by invoking the `fit` method and passing the
# training data set.
estimator.fit(input_fn=input_fn, steps=1000)
# Here we evaluate how well our model did. In a real example, we would want
# to use a separate validation and testing data set to avoid overfitting.
estimator.evaluate(input_fn=input_fn)
実行すると以下のように出力されます。
{'global_step': 1000, 'loss': 1.9650059e-11}
カスタム・モデル
tf.contrib.learnはあなたをあらかじめ定義されたモデルだけに縛ることはしません。
例えば、TensorFlowに組み込まれていないカスタムモデルを作成したかったとします。tf.contrib.learnのデータセット、フィード、トレーニングなどの高レベルの抽象化は引き続き保持できます。説明のために、低レベルのTensorFlow APIに関する知識を使用して、LinearRegressorに独自の同等のモデルを実装する方法を以下に示します。
tf.contrib.learnで動作するカスタムモデルを定義するには、tf.contrib.learn.Estimatorを使用する必要があります。 tf.contrib.learn.LinearRegressorは実際には、tf.contrib.learn.Estimatorのサブクラスになります。Estimatorをサブクラス化するのではなく、予測、トレーニングの手順、および損失を評価する方法をtf.contrib.learnに通知する関数model_fnをEstimatorに提供するだけです。コードは次のようになります。
import numpy as np
import tensorflow as tf
# Declare list of features, we only have one real-valued feature
def model(features, labels, mode):
# Build a linear model and predict values
W = tf.get_variable("W", [1], dtype=tf.float64)
b = tf.get_variable("b", [1], dtype=tf.float64)
y = W*features['x'] + b
# Loss sub-graph
loss = tf.reduce_sum(tf.square(y - labels))
# Training sub-graph
global_step = tf.train.get_global_step()
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = tf.group(optimizer.minimize(loss),
tf.assign_add(global_step, 1))
# ModelFnOps connects subgraphs we built to the
# appropriate functionality.
return tf.contrib.learn.ModelFnOps(
mode=mode, predictions=y,
loss=loss,
train_op=train)
estimator = tf.contrib.learn.Estimator(model_fn=model)
# define our data set
x = np.array([1., 2., 3., 4.])
y = np.array([0., -1., -2., -3.])
input_fn = tf.contrib.learn.io.numpy_input_fn({"x": x}, y, 4, num_epochs=1000)
# train
estimator.fit(input_fn=input_fn, steps=1000)
# evaluate our model
print(estimator.evaluate(input_fn=input_fn, steps=10))
実行すると、以下のように出力されます。
{'loss': 5.9819476e-11, 'global_step': 1000}
カスタムmodel()関数の内容が、下位レベルのAPIの手動モデルトレーニングループと非常に類似している点に注目してください。
次のステップ
このチュートリアルを通して、あなたはTensorFlowの基礎に関する実践的な知識を得ました。もっと詳しく学ぶには、いくつかチュートリアルをご覧ください。機械学習の初心者の方は、「機械学習初心者のためのMNIST(翻訳)」を、それ以外であれば「Deep MNIST for Experts」(English)をご覧ください。