本記事は、TensorFlow(テンソルフロー)の本家サイト「TensorBoard: Visualizing Learning」 を翻訳(適宜意訳)したものです。誤り等あればご指摘いただけたら幸いです。
TensorBoard:学習の可視化
大規模な深いニューラルネットワークのトレーニングのようなTensorFlowを使用する計算は、複雑で紛らわしいものになります。 TensorFlowプログラムの理解、デバッグ、および最適化を容易にするために、TensorBoardという一連の視覚化ツールが含まれています。 TensorBoardを使用して、TensorFlowグラフを視覚化し、グラフの実行に関する定量的なメトリックをプロットし、それを通過する画像のような追加のデータを表示することができます。 TensorBoardが設定されると、次のようになります。
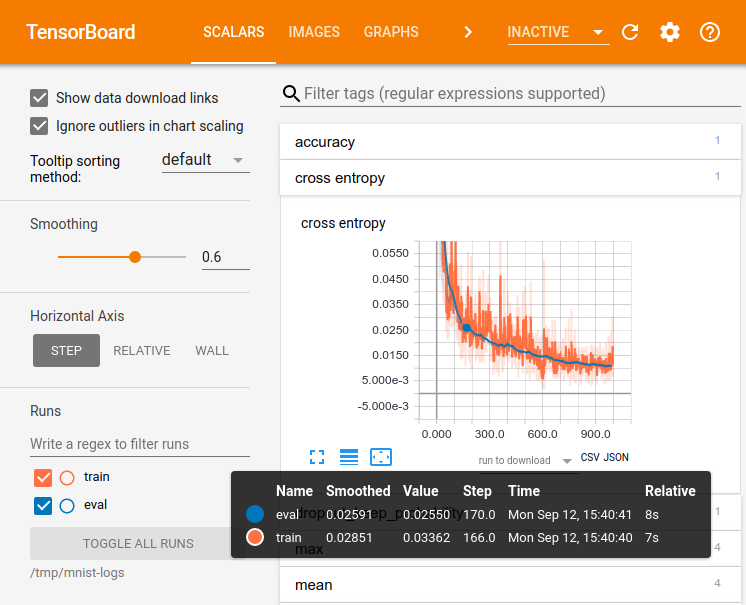
このチュートリアルは、TensorBoardを簡単に使い始められることを目的としています。他にも利用可能なリソースがあります! TensorBoard READMEには、ヒントやテクニック、デバッグ情報など、TensorBoardの使い方に関する多くの情報があります。
データのシリアライズ
TensorBoardは、TensorFlowを実行するときに生成できるサマリーデータ1を含むTensorFlowイベントファイルを読み込むことによって動作します。TensorBoard内のサマリーデータの一般的なライフサイクルを以下に示します。
まず、サマリーデータを収集するTensorFlowグラフを作成し、サマリーオペレーション2で注釈を付けるノードを決定します。
たとえば、MNISTの数字を認識するために畳み込みニューラルネットワークをトレーニングしているとします。学習率が時間の経過と共にどのように変化するか、目的関数がどのように変化しているかを記録したいはずです。学習率と損失をそれぞれ出力するノードに tf.summary.scalar を付けることで、これらの必要な情報を収集します。それから、scalar_summaryに、「learning rate3」や「loss function4」のような意味のあるタグを付けます。
特定のレイヤーから取り除かれたアクティベーションの分布、またはグラデーションやウェイトの分布を視覚化することもできます。このデータを収集するには、tf.summary.histogram を勾配の出力と重みを保持する変数にそれぞれ追加します。
利用可能なすべての操作の詳細については、操作に関するドキュメントを参照してください。
TensorFlowのオペレーションは、実行するまで何もしません。また、オペレーションは出力に依存します。作成したばかりのサマリーノードはグラフの周辺にあり、現在実行しているオペレーションはどれもそれらに依存していません。したがって、サマリーを生成するには、これらのサマリー・ノードをすべて実行する必要があります。それらを手で管理するのは面倒なので、tf.summary.merge_allを使用してそれらをまとめて、すべてのサマリー・データを生成する単一のオペレーションにします。
マージされたサマリーオペレーションを実行するだけで、指定されたステップですべてのサマリーデータを含むシリアライズされたSummaryオブジェクトが生成されます。最後に、このデータをディスクに書き込むには、Summaryオブジェクトをtf.summary.FileWriterに渡します。
FileWriterは、コンストラクタ内でlogdir(ログディレクトリー)をとります。このlogdirは非常に重要で、すべてのイベントが書き出されるディレクトリです。また、FileWriterはオプションで、そのコンストラクタ内でGraphを取り込むことができます。 Graphオブジェクトを受け取った場合、TensorBoardは、Tensorの形状情報とともにグラフを視覚化します。これにより、グラフを流れるものの感覚をよりよく知ることができます。詳しくは、「Tensor shape information」を参照してください。
グラフを変更してFileWriterを作成したら、ネットワークを起動する準備が整いました!必要に応じて、1ステップごとにマージされたサマリーオペレーションを実行し、たくさんのトレーニングデータを記録することができます。しかし、それは必要以上に多いデータになる可能性がありますので、代わりに、マージされた集計演算をnステップごとに実行することを検討しましょう。
以下のコードは、「simple MNIST tutorial」を変更したものです。ここでは、いくつかのサマリーオペレーションを追加し、10ステップごとに実行しています。これを実行しtensorboard --logdir=/tmp/tensorflow/mnistを実行すると、トレーニング中に重みや精度がどのように変化したかなどの統計データを視覚化することができます。以下にコードの抜粋を載せます。完全なソースコードはこちらを参照してください。
def variable_summaries(var):
"""Attach a lot of summaries to a Tensor (for TensorBoard visualization)."""
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
tf.summary.histogram('histogram', var)
def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):
"""Reusable code for making a simple neural net layer.
It does a matrix multiply, bias add, and then uses relu to nonlinearize.
It also sets up name scoping so that the resultant graph is easy to read,
and adds a number of summary ops.
"""
# Adding a name scope ensures logical grouping of the layers in the graph.
with tf.name_scope(layer_name):
# This Variable will hold the state of the weights for the layer
with tf.name_scope('weights'):
weights = weight_variable([input_dim, output_dim])
variable_summaries(weights)
with tf.name_scope('biases'):
biases = bias_variable([output_dim])
variable_summaries(biases)
with tf.name_scope('Wx_plus_b'):
preactivate = tf.matmul(input_tensor, weights) + biases
tf.summary.histogram('pre_activations', preactivate)
activations = act(preactivate, name='activation')
tf.summary.histogram('activations', activations)
return activations
hidden1 = nn_layer(x, 784, 500, 'layer1')
with tf.name_scope('dropout'):
keep_prob = tf.placeholder(tf.float32)
tf.summary.scalar('dropout_keep_probability', keep_prob)
dropped = tf.nn.dropout(hidden1, keep_prob)
# Do not apply softmax activation yet, see below.
y = nn_layer(dropped, 500, 10, 'layer2', act=tf.identity)
with tf.name_scope('cross_entropy'):
# The raw formulation of cross-entropy,
#
# tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(tf.softmax(y)),
# reduction_indices=[1]))
#
# can be numerically unstable.
#
# So here we use tf.nn.softmax_cross_entropy_with_logits on the
# raw outputs of the nn_layer above, and then average across
# the batch.
diff = tf.nn.softmax_cross_entropy_with_logits(targets=y_, logits=y)
with tf.name_scope('total'):
cross_entropy = tf.reduce_mean(diff)
tf.summary.scalar('cross_entropy', cross_entropy)
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(FLAGS.learning_rate).minimize(
cross_entropy)
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
# Merge all the summaries and write them out to /tmp/mnist_logs (by default)
merged = tf.summary.merge_all()
train_writer = tf.summary.FileWriter(FLAGS.summaries_dir + '/train',
sess.graph)
test_writer = tf.summary.FileWriter(FLAGS.summaries_dir + '/test')
tf.global_variables_initializer().run()
FileWriterを初期化した後、FileWriterにサマリーを追加して、モデルのトレーニングとテストを行います。
# Train the model, and also write summaries.
# Every 10th step, measure test-set accuracy, and write test summaries
# All other steps, run train_step on training data, & add training summaries
def feed_dict(train):
"""Make a TensorFlow feed_dict: maps data onto Tensor placeholders."""
if train or FLAGS.fake_data:
xs, ys = mnist.train.next_batch(100, fake_data=FLAGS.fake_data)
k = FLAGS.dropout
else:
xs, ys = mnist.test.images, mnist.test.labels
k = 1.0
return {x: xs, y_: ys, keep_prob: k}
for i in range(FLAGS.max_steps):
if i % 10 == 0: # Record summaries and test-set accuracy
summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False))
test_writer.add_summary(summary, i)
print('Accuracy at step %s: %s' % (i, acc))
else: # Record train set summaries, and train
summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True))
train_writer.add_summary(summary, i)
これでTensorBoardを使用して、データを視覚化できるようになりました。
TensorBoardを起動する
TensorBoardを実行するには、次のコマンドを使用します(あるいは、python -m tensorflow.tensorboard)
tensorboard --logdir=path/to/log-directory
logdirは、FileWriterがデータをシリアライズしたディレクトリを指します。このlogdirディレクトリに、別々の実行でシリアライズされたデータを含むサブディレクトリが含まれている場合、TensorBoardはそれらのすべての実行からのデータを視覚化します。TensorBoardが起動したら、Webブラウザからlocalhost:6006にアクセスすると、TensorBoardが表示されます。
TensorBoardの画面右上にナビゲーションタブが表示されます。各タブは、可視化できる一連のシリアライズされたデータを表します。
グラフタブを使用してグラフを視覚化する方法の詳細については、「TensorBoard: Graph Visualization」を参照してください。
また、TensorBoardの一般的な使用方法については、「TensorBoard README」を参照してください。