機械学習が流行っています。多くの人が機械学習について一度は聞いたことがあるのではないでしょうか。
この記事では、iOS 11で導入された新しいフレームワークであるCore ML と Visionを紹介します。具体的には、これらの新しいAPIをPlaces205-GoogLeNetモデルで使用して画像を分類する方法を紹介します。詳細は、Appleの機械学習ページをご参照ください。
[aside type=”normal”]
Xcode 9 Beta 1以降、Swift 4、およびiOS 11が必要です。
[/aside]
スタータープロジェクトから始めてみる
スタータープロジェクトをダウンロードしてください。画像を表示し、ユーザーが写真ライブラリから別の画像を選択できるUiが既に組み込まれています。なので、このスタータープロジェクトを利用することで、機械学習とデザイン部分の実装に集中することができます。
プロジェクトをビルドして実行します。

すでに、Info.plistにPrivacy – Photo Library Usage Descriptionがあるため、使用の許可を聞かれる場合があります。
画像とボタンの間にはラベルがあり、画像の分類が表示されるはずです。
Appleは何を提供しているのか
AppleはiOS 5にて、自然言語を分析するためにNSLinguisticTaggerを導入しました。NSLinguisticTaggerを用いると、自然言語のテキストを品詞(名詞、動詞、代名詞)や「個人名」「地名」といった属性で分類することができます。iOS 8ではMetalが搭載され、デバイスのGPUへのアクセスを可能としました。
2016年に、AppleはBasic Neural Network Subroutines(BNNS)をAccelerateフレームワークに追加し、推論のためのニューラルネットワークを構築できるようにしました。
そして2017年、AppleはCore MLとVisionをリリースしました。
・Core MLを利用することで、アプリで訓練されたモデルの扱いがさらに簡単になります。
・Visionを利用することで、顔、テキスト、長方形、バーコード、等のようなオブジェクトを検出するモデルを簡単に使えるようになります。
また、この記事の中のソースで使っているVisionモデルで、画像解析Core MLモデル(image-analysis Core ML model)をラップすることもできます。これら2つのフレームワークはMetal上に構築されているため、デバイス上で効率的に実行されます。なので、ユーザーのデータをサーバーに送信する必要はありません。
Core MLモデルをアプリケーションに組み込む
この記事では、Appleの機械学習ページからダウンロードできるPlaces205-GoogLeNetモデルを使用します。ページをスクロールし、Working with ModelsのPlaces205-GoogLeNetをダウンロードします。また、その下の他の3つのモデルに注目してください。これらのモデルはすべて、木、動物、人などのオブジェクトを画像内で検出することができます。
Caffe、Keras、scikit-learnなど、サポートされている機械学習ツールを使用して訓練済みモデルを作成している場合は、Converting Trained Models to Core MLページでCore MLフォーマットに変換する方法が説明されています。
モデルをプロジェクトに追加する
GoogLeNetPlaces.mlmodelをダウンロードした後、プロジェクトのProject NavigatorのResourcesディレクトリにドラッグします。

しばらく待つと、Xcodeがモデルクラスを生成され、以下の画面のように矢印が表示されます。
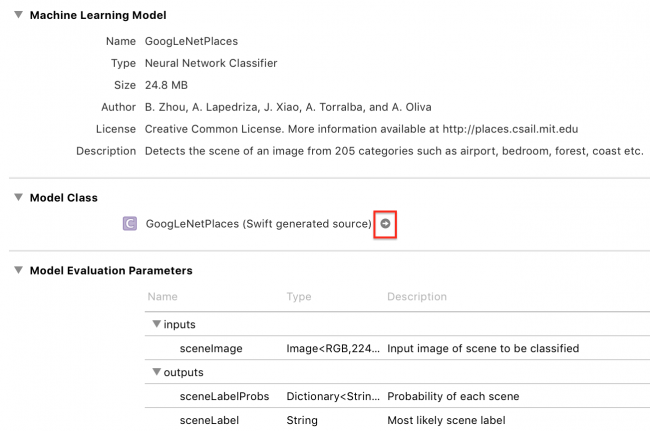
矢印をクリックすると、生成されたクラスが表示されます。

Xcodeは入力クラスと出力クラスを生成し、メインクラスのGoogLeNetPlacesはモデルプロパティと2つのpredictionメソッドを持っています。
GoogLeNetPlacesInputには、CVPixelBuffer型のsceneImageプロパティがあります。これにより、Visionフレームワークは、おなじみの画像フォーマットを正しい入力タイプに変換する処理を行ってくれます。
また、VisionフレームワークはGoogLeNetPlacesOutputプロパティを独自の結果タイプに変換し、predictionメソッドの呼び出しを管理します。なので、生成された全てのコードのうち、モデルプロパティのみが使用されます。
VisionモデルにおけるCore MLモデルのラッピング
ViewController.swiftを開き、2つのフレームワークをインポートします。
import CoreML import Vision
次に、IBActionsエクステンションの下に次のコードを追加します。
// MARK: - Methods
extension ViewController {
func detectScene(image: CIImage) {
answerLabel.text = "detecting scene..."
// Load the ML model through its generated class
guard let model = try? VNCoreMLModel(for: GoogLeNetPlaces().model) else {
fatalError("can't load Places ML model")
}
}
}
やっていることは次のとおりです
まず、何かが起こっているかをメッセージで表示します。
GoogLeNetPlacesはエラーをスローするので、作成時にtryを使用します。
VNCoreMLModelは、Visionからのリクエストで使用されるCore MLモデルのコンテナです。
標準的なVisionのワークフローは、モデルを作成し、1つ以上のリクエストを作成してから、リクエストハンドラを作成して実行することです。モデルを作成したら、次のステップはリクエストを作成します。
detectScene(image:)の最後に次の行を追加します。
// Create a Vision request with completion handler
let request = VNCoreMLRequest(model: model) { [weak self] request, error in
guard let results = request.results as? [VNClassificationObservation],
let topResult = results.first else {
fatalError("unexpected result type from VNCoreMLRequest")
}
// Update UI on main queue
let article = (self?.vowels.contains(topResult.identifier.first!))! ? "an" : "a"
DispatchQueue.main.async { [weak self] in
self?.answerLabel.text = "\(Int(topResult.confidence * 100))% it's \(article) \(topResult.identifier)"
}
}
VNCoreMLRequestは、Core MLモデルを使用して作業を行う画像分析リクエストです。リクエストオブジェクトとエラーオブジェクトを受け取ります。
request.resultsが、VNClassificationObservationオブジェクトの配列であることがわかります。VNClassificationObservationオブジェクトの配列は、Core MLモデルが予測子またはイメージプロセッサではなく、分類子である場合にVisionフレームワークが返すオブジェクトです。GoogLeNetPlacesは1つの特徴(画像の分類)のみを予測します。
次のステップに進みます。リクエストハンドラの作成と実行です。
detectScene(image :)の最後に次の行を追加します。
// Run the Core ML GoogLeNetPlaces classifier on global dispatch queue
let handler = VNImageRequestHandler(ciImage: image)
DispatchQueue.global(qos: .userInteractive).async {
do {
try handler.perform([request])
} catch {
print(error)
}
}
VNImageRequestHandlerはVisionフレームワークのリクエストハンドラです。引数としてdetectScene(image :)に入っている画像を受け取ります。次に、performメソッドを呼び出して、リクエストの配列を渡して、実行します。
performメソッドはエラーを投げるので、try-catchで囲みます。
モデルを使用して画像を分類する
モデルを使用して画像を分類するには、detectScene(image :)を2つの場所で呼び出すだけです。
viewDidLoad()の最後とimagePickerController(_:didFinishPickingMediaWithInfo :)の最後に次の行を追加します:
guard let ciImage = CIImage(image: image) else {
fatalError("couldn't convert UIImage to CIImage")
}
detectScene(image: ciImage)
ソースをビルドして実行します。分類に時間はかかりません。

ボタンをタップし、フォトライブラリの画像を選択します。