本記事は、Tensorflowの本家サイトの「TensorBoard: Embedding Visualization」を翻訳(適宜意訳)したものです。誤り等あればご指摘いただけたら幸いです。
TensorBoard:Embedding Visualizationを動かす
Embeddingは、機械学習、レコメンデーションシステム、NLP、および他の多くのアプリケーションに利用されています。実際、TensorFlowのコンテキストでは、テンソル(またはテンソルの一部)を空間上の点として見ることができます。ほとんどのTensorFlowシステムは自然にさまざまな埋め込みが可能です。
TensorBoardは、埋め込みのような高次元のデータのインタラクティブな視覚化と解析のために、Embedding Projectorと呼ばれるビルトインビジュアライザを備えています。Embedding Projectorは、あなたのモデルのチェックポイントファイルを読み込みます。トレーニングの重みを含む2Dテンソルも読み込みます。
埋め込みとその学習方法の詳細については、「Vector Representations of Words」チュートリアルを参照してください。画像の埋め込みに興味がある場合は、こちらの記事でMNIST画像の興味深い視覚化をチェックしてください。また、単語の埋め込みに興味がある場合は、こちらの記事を参考にしてください。
デフォルトでは、Embedding Projectorは principal component analysis(主成分分析)を使用して高次元データを3次元に投影します。PCAの視覚的な説明については、こちらの記事を参照してください。あなたが使うことができる別の非常に有用な投影法はt-SNEです。このチュートリアルの後半で、t-SNEの詳細について説明します。
埋め込みを使用している場合は、データポイントにラベルや画像を添付することをお勧めします。これを行うには、各ポイントのラベルを含むメタデータファイルを生成し、Python APIを使用してプロジェクタを設定するか、手動でチェックポイントファイルと同じディレクトリにprojector_config.pbtxtを作成して保存します。
セットアップ
TensorBoardを実行し、必要な情報をすべて記録する方法の詳細については、「TensorBoard:Visualizing Learning」を参照してください。
埋め込みを視覚化するには、以下の3つのことが必要です。
1)埋め込みを保持する2Dテンソルを設定します。
embedding_var = tf.Variable(....)
2)LOG_DIRのチェックポイントにモデル変数を定期的に保存します。
saver = tf.train.Saver() saver.save(session, os.path.join(LOG_DIR, "model.ckpt"), step)
3)(任意)埋め込みにメタデータを関連付けます。
あなたの埋め込みに関連するメタデータ(ラベル、画像)がある場合は、それをLOG_DIRに直接project_config.pbtxtを保存するか、Python APIを使用してTensorBoardに伝えることができます。
たとえば、次のprojector_config.ptxtはword_embedding tensor を $LOG_DIR/metadata.tsv に格納されているメタデータに関連付けます。
embeddings {
tensor_name: 'word_embedding'
metadata_path: '$LOG_DIR/metadata.tsv'
}
次のコードを使用して、プログラムで同じ設定を生成できます。
from tensorflow.contrib.tensorboard.plugins import projector # Create randomly initialized embedding weights which will be trained. N = 10000 # Number of items (vocab size). D = 200 # Dimensionality of the embedding. embedding_var = tf.Variable(tf.random_normal([N,D]), name='word_embedding') # Format: tensorflow/tensorboard/plugins/projector/projector_config.proto config = projector.ProjectorConfig() # You can add multiple embeddings. Here we add only one. embedding = config.embeddings.add() embedding.tensor_name = embedding_var.name # Link this tensor to its metadata file (e.g. labels). embedding.metadata_path = os.path.join(LOG_DIR, 'metadata.tsv') # Use the same LOG_DIR where you stored your checkpoint. summary_writer = tf.summary.FileWriter(LOG_DIR) # The next line writes a projector_config.pbtxt in the LOG_DIR. TensorBoard will # read this file during startup. projector.visualize_embeddings(summary_writer, config)
モデルを実行しトレーニングした後、ジョブのLOG_DIRを指定して、TensorBoardを実行します。
tensorboard --logdir=LOG_DIR
次に、上部ペインのEmbeddingsタブをクリックし、適切な実行を選択します(実行が複数ある場合)。
メタデータ
通常、埋め込みにはそれに関連付けられたメタデータ(ラベル、画像など)があります。メタデータはモデルのトレーニング可能なパラメータではないため、メタデータはモデルチェックポイント以外の別のファイルに格納する必要があります。フォーマットはTSVファイル(タブ文字は\tで表示)で、最初の行には列ヘッダが続き、その後の行にはメタデータ値が含まれます。
Word\tFrequency
Airplane\t345
Car\t241
...
メインデータファイルと共有される明示的なキーはありません。代わりに、メタデータファイル内の順序は、埋め込みテンソル内の順序と一致すると仮定されます。すなわち、1行目はヘッダ情報であり、メタデータファイルの(i+1)行目は、チェックポイントに格納されている埋め込みテンソルのi行目に対応します。
[aside type=”normal”]
TSVメタデータファイルに列が1つしかない場合は、ヘッダー行は必要なく、各行が埋め込みのラベルであると想定します。これは、一般的に使用されている「vocabファイル」形式と一致するため、この例外が存在します。
[/aside]
画像
埋め込みに関連付けられた画像がある場合、各データポイントの小さなサムネイルで構成される単一の画像を生成する必要があります。これはsprite image(スプライト画像)と呼ばれます。スプライトの行数と列数は、最初のデータポイントが左上に、最後のデータポイントが右下に順番に格納されている必要があります。

上記の例では、最後の行を埋める必要はありません。スプライト画像の具体例については、こちらの記事を参照してください。(10,000個のMNISTディジット(100×100)のスプライトイメージ)
[aside type=”normal”]
現在、8192px X 8192pxまでのスプライトをサポートしています。
[/aside]
スプライトを作成したら、埋め込みプロジェクタにどこにそれを見つけるかを伝える必要があります:
embedding.sprite.image_path = PATH_TO_SPRITE_IMAGE # Specify the width and height of a single thumbnail. embedding.sprite.single_image_dim.extend([w, h])
インタラクション(相互作用)
Embedding Projectorには3つのパネルがあります。
- 左上のデータパネル。ここでは、実行、テンソルとデータの埋め込み列を選択して、ポイントを色付けしてラベル付けすることができます。
- 左下の投影パネル(PCA、t-SNEなど)を選択します。
- 右側のインスペクタパネルでは、特定のポイントを検索し、最寄りのリストを表示することができます。
投影
Embedding Projectorには、データセットの次元数を減らす3つの方法があります。2つは線形、もう1つは非線形です。各メソッドを使用して、2次元または3次元のビューを作成できます。
Principal Component Analysis(PCA)
次元を縮小するための簡単な手法です。Embedding Projectorは、上位10個の主成分を計算します。このメニューでは、これらのコンポーネントを2つまたは3つの任意の組み合わせに投影できます。PCAは線形投影法であり、多くの場合、グローバルジオメトリの検証に有効です。
t-SNE
一般的な非線形次元削減技術はt-SNEです。Embedding Projectorは、2次元および3次元のt-SNEビューの両方を提供します。レイアウトは、アルゴリズムのすべてのステップをアニメーション化するクライアント側で実行されます。t-SNEはしばしばいくつかの局所構造を保存するので、局所近傍を探索してクラスタを見つけるのに有益です。高次元のデータを視覚化するのに非常に便利ですが、時にt-SNEプロットはミステリアスな部分があるため誤解を招くことがあります。t-SNEを効果的に使用する方法については、こちらの記事を参照してください。
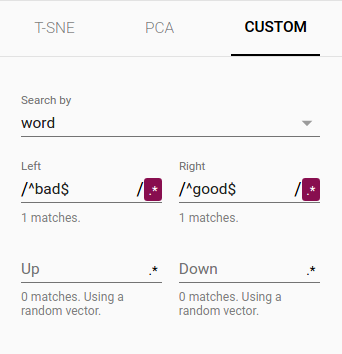
Custom
カスタムスペース内で意味のある方向を見つけるためのテキスト検索に基づいて、特殊な線形投影を構築することもできます。投影軸を定義するには、2つの検索文字列または正規表現を入力します。プログラムは、ラベルがこれらの検索と一致する点の集合の重心を計算し、重心間の差のベクトルを投影軸として使用します。
ナビゲーション
データセットを探索するには、クリックアンドドラッグで、2Dモードまたは3Dモードのいずれかでビューをナビゲートしたり、ズーム、回転、パンすることができます。あるポイントをクリックすると、右の区画に、現在のポイントまでの距離と共に、最も近い明示的なテキストリストが表示されます。投影上で強調表示されます。
クラスタを拡大していくと情報が得られますが、ビューの一部をポイントに限定し、それらのポイントでのみ投影を実行すると便利な場合があります。これを行うには、複数の方法でポイントを選択することができます。
- ポイントをクリックすると、その最近傍点も選択されます。
- 検索後、クエリと一致するポイントが選択されます。
- 選択を有効にし、ポイントをクリックしてドラッグすると、選択範囲が定義されます。
ポイントのセットを選択すると、右側のインスペクタペインの「Isolate Points」ボタンを使用して、それらのポイントを分離してさらに解析することができます。
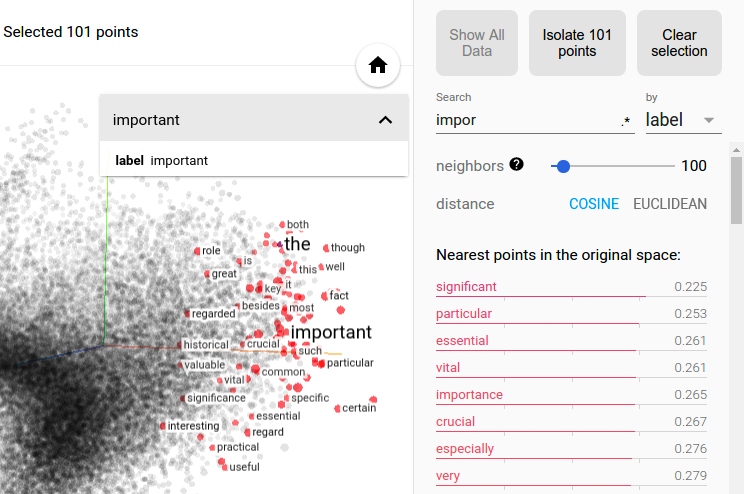
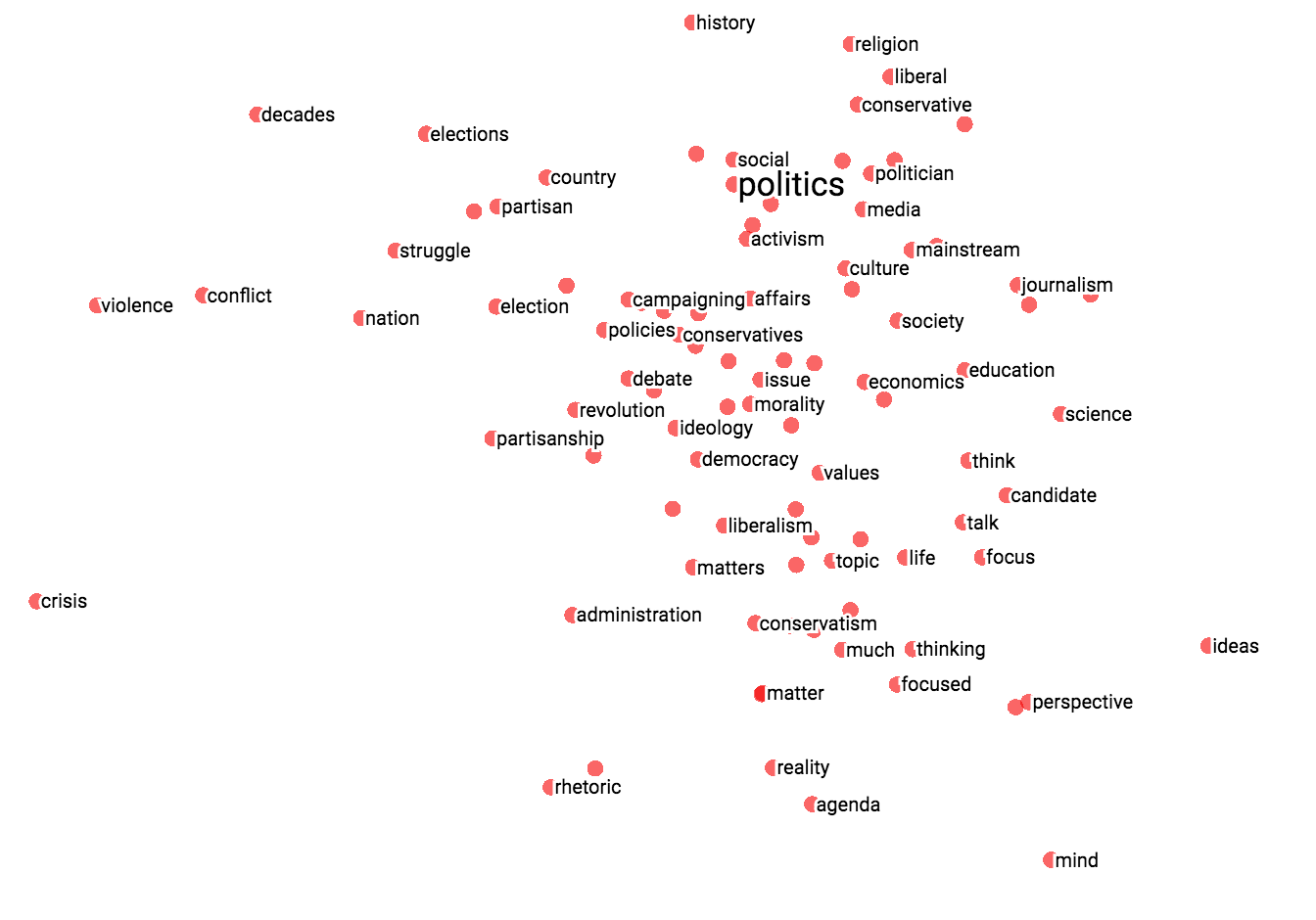
フィルタリングとカスタムプロジェクションの組み合わせは強力です。以下では、100の「政治」に関する単語の近似値をフィルタリングし、それらを「最悪」のベクトルのx軸として投影しました。y軸はランダムです。
右側には「アイデア」「科学」「パースペクティブ」「ジャーナリズム」があり、左側には「危機」「暴力」「紛争」があります。
|
|
コラボレーション機能
検索結果を共有するには、右下隅にあるブックマークパネルを使用して、現在の状態(投影の計算座標を含む)を小さなファイルとして保存します。プロジェクタは、これらのファイルの1つまたは複数のセットを指定でき、以下のパネルを生成します。他のユーザは、関連のブックマークを見ることができます。